필자는 어제 면접을 보고 왔다.
면접 중 너무 어이없는 경험을 하였는데 프로젝트에 대한 답변은 잘하면서도, LLM 기초, 전공 지식에 대해 질문을 받으면 말문이 막히는거다. 물론 머리로는 대충 알고 있다. 이게 어떻게 동작하고 언제 쓰이는지. 근데 이게 말로 표현이 안된다. 와 이러면 내가 잘 알고 있다고 말할 수 있나?
이러한 의문이 들어 알고 있는 것도 글로, 말로 재정리해보는 시간을 가지기로 하였다.
일단 Transformer가 뭐더라?
Transformer는 기존의 seq2seq의 인코더-디코더를 구조를 따르면서도 어텐션 메커니즘만을 사용하여 구현된 모델이다.
기존의 seq2seq 모델은 인코더-디코더 구조로 이루어져 있으며, RNN(순환신경망)을 사용한다. 인코더에서 순차적으로 입력 텍스트에 대한 액기스(하나의 벡터 표현)를 추출하여 디코더에 이를 기반으로 출력 시퀀스를 생성한다고 생각하면 이해하기 쉽다. 하지만 이러한 액기스를 추출할 때 액기스를 매우 작은 하나의 표현으로 압축시키기 때문에 또 정보가 손실될 수 있다는 점, 특히 순차적이어서 초반부의 정보를 제대로 활용하지 못하는 점(long-term dependency)이 문제였다.
따라서 transformer는 어텐션을 도입하여 이러한 문제를 해결하였다.
transformer에서 어텐션의 기본 아이디어는 “디코더가 출력 단어를 예측하는 각 시점마다 인코더에서의 전체 입력 문장을 다시 한 번 더 참고하자. 근데 인코더의 모든 문장을 같은 비중으로 참고하지 말고 해당 시점에서 예측해야 할 단어와 관련 있는 입력 단어 부분에 좀 더 집중하면서 참고하자”이다.

어텐션 함수는 주어진 Query에 대해 모든 Key와의 유사도(관련성)을 계산하고, 이를 Value에 반영한다.
Transformer의 decoder의 cross-attention에서
- Query: 디코더에서 masked self-attention을 거친, 디코더 셀의 은닉 상태들
- Key: 인코더에서 self-attention을 거쳐서 서로의 관련성을 완벽히 반영한, 인코더 셀의 은닉 상태들
- Value: Query와 같은 디코더 셀의 은닉 상태들
Q, K, V를 이와 같이 두고 어텐션 연산을 하게 되면, 디코더 셀의 은닉 상태들이 인코더에서의 전체 입력 문장을 다시 한번 참고할 수 있게 되는 것이다.
어텐션 연산은 아래와 같은 그림처럼 표현할 수 있는데,
- Query와 Key의 관련성을 계산 ⇒ Q x K^T
- 그 관련성을 Value에 반영 ⇒ Q x K^T x V

Attention Mechanism
그러면 Transformer에서 어떻게 우리가 흔히 알던 LLM이 나온 것일까?
전에 작성했다시피 Transformer는 Encoder와 Decoder가 합해진 구조다.
Transformer Encoder는 입력 문장의 모든 단어를 동시에 보는, Masking 없는 Self-Attention을 수행한다. 흔히 임베딩할 때 많이 사용하는 BERT도 트랜스포머의 인코더를 떼와서 만든 모델로, 양방향 정보를 활용하여 표현을 생성한다.
이와 달리, GPT는 트랜스포머의 디코더를 떼와서 만든 모델인데, 미래의 단어를 보지 못하도록 Masked Self-Attention을 수행한다. GPT는 기본적으로 다음 토큰을 예측하도록 하는 인과 관계 모델링 목표에 기반하여 사전 학습된다. 이러한 LLM은 토큰 리스트를 입력으로 받아 중단 기준(생성할 토큰 수 제한이나 중단 단어 생성)에 충족할 때까지 후속 토큰을 자동 회귀적으로 생성한다.
LLM이 출력을 생성하는 단계에는 입력 처리(prefill) 단계와 출력 생성(decode) 단계, 총 두 단계로 설명할 수 있다.
1. 입력 처리(prefill) 단계에서는 입력 프롬프트에 대한 토큰들을 처리하여 Key, Value를 연산하고, 첫 번째 새로운 토큰을 생성한다. 이 단계에서는 입력의 전체 범위에 대해 연산을 하기 때문에 Self-Attention 연산에서 행렬-행렬 연산이 사용되어 GPU를 엄청 사용하게 된다.
2. 출력 생성(decode) 단계에서 LLM은 중단 기준이 충족될 때까지 출력 토큰을 하나씩 회귀적으로 생성한다. 이전 토큰 생성 과정에서의 Key, Value를 저장하고 있기에(후에 KV 캐시에 대해 설명 예정), Self-Attention 연산에서 벡터-행렬 연산이 사용되어 비교적 GPU를 적게 사용한다. 따라서 계산에 소요되는 시간보다는 데이터(가중치, 키, 값, 활성화 값)이 메모리에서 GPU로 전송되는 속도가 지연 시간을 결정한다. (Memory-Bound 연산)
GPT에 대한 더 자세한 설명이 궁금하다면 아래의 링크를 추천한다.
Paper Review | Improving Language Understanding by Generative Pre-Training (GPT-1)
What did authors try to accomplish?문제점과 해결방법을 기반으로 해당 논문에서 기여한 바문제점: unlabeled data가 풍족한 것에 비해, 특정 작업을 위한 labeled data는 부족하다.해결방법:GPT(Generative Pre-trained
soyoonblog.tistory.com
LLM이 샘플링을 수행하는 과정을 예제와 함께 살펴보자.
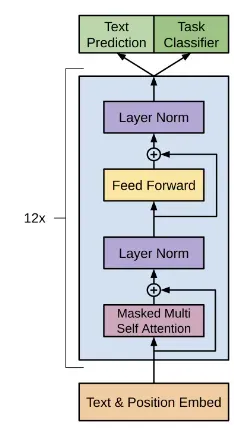
이 예제에서는 입력 처리 단계의 과정에 대해 알아보고, 후에 KV 캐시에 대해 설명할 때 출력 생성 단계를 설명하도록 하겠다.
입력 프롬프트는 “hello how are you”이고 예측할 다음 토큰은 “?”라고 가정하고 진행할 것이다.
1. 토큰화 및 임베딩 변환
입력 텍스트인 “hello how are you”는 토큰화를 거쳐 [”hello”, “how”, “are”, "you"]의 토큰들로 쪼개진다.
각 토큰을 모델의 임베딩 층을 통해 d-차원의 벡터로 변환되며, 이를 수식으로 표현하면 다음과 같다.
이 때 X_1, X_2, X_3, X_4는 각각 “hello”, “how”, “are”, "you"의 벡터 표현이라고 볼 수 있다.
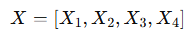
2. Query, Key, Value 행렬 생성
트랜스포머는 각 토큰에 대해 Query(Q), Key(K), Value(V) 행렬을 생성한다. 각 임베딩 X_i에 대해 학습 가능한 가중치 W_Q, W_K, W_V를 곱하여 Q_i, K_i, V_i를 얻는다.

이를 모든 토큰에 대해 수행하면, 다음 수식과 같다.
실제 연산에서는 4개(입력 토큰의 개수) 의 행으로 구성된 임베딩 행렬(4 x d)과 가중치 행렬(d x m)을 곱하는 형태로 한번에 이루어진다. ⇒ Q, K, V (4 x m)
이 연산을 통해 각 토큰들을 어떻게 바라볼 지에 대한 관점을 입혀주는 과정을 거친다. 특히 Multi-head attention에서는 이 변환을 여러 번 나눠 수행하여 다양한 관점에서 토큰들을 인식하도록 한다.
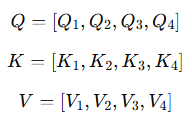
3. Attention Score 계산
“hello”, “how”, “are”, "you" 네 토큰들간의 연관성을 참고하도록 Attention Score를 계산하자.
Attention Score 행렬 S는 Query 행렬과 Key 행렬의 내적을 통해 계산된다.
각 Query 벡터 Q_i와 Key 벡터 K_j 간의 내적을 계산하여 현재 토큰 i와 다른 토큰 j의 연관성(유사도) 점수를 구한다.
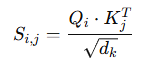
즉, Query 행렬(4 x m)과 Key 행렬(4 x m)의 전치 행렬이 곱해져 Attention Score 행렬 S (4 x 4)을 얻게 된다.
이 과정에서 Query-Key간의 유사도를 추출할 수 있다.

4. Softmax를 적용하여 Attention Weight 계산
각 행에 Softmax를 적용하여 Attention Score를 확률 값으로 변환한 후, Attention Weight 행렬 A를 얻게 된다. 이 행렬의 각 값들은 해당 토큰이 다른 토큰을 얼마나 중요하게 여기는지를 나타낸다.
5. Attention Output 계산
Attention Weight 행렬 A(4 x 4)와 Value 행렬(4 x m)을 곱하여 토큰들간의 유사도, 즉 문맥을 반영한 새로운 행렬(4 x m)을 구할 수 있다.
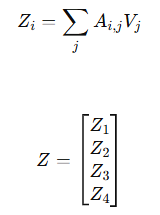
6. 다음 토큰 예측
이후 Attention 연산, Layer Normalization, Feedforward Network 등을 거친 후, 최종 출력 벡터에 대해 softmax를 적용하여 다음 토큰을 예측한다. 일반적으로는 결과 확률 분포 중 가장 확률이 높은 토큰(”?”)을 다음 토큰으로 샘플링한다.

이러한 과정을 또 반복하면서 “hello how are you?” 다음에 올 토큰을 예측한다.

KV 캐시: 기존 토큰들에 대한 Key, Value를 다시 계산하는 것은 비효율적이지 않나?
근데 여기서 효율 관점 의문이 생길 수 있다.
“hello how are you”에 대한 셀프 어텐션은 이미 계산했었는데 새로운 토큰이 추가될 때마다 기존 토큰들에 대한 Key, Value를 다시 계산해야 하는 것일까? 연산 중복 아닌가?
이러한 의문에서 나온 것이 KV 캐시이다.
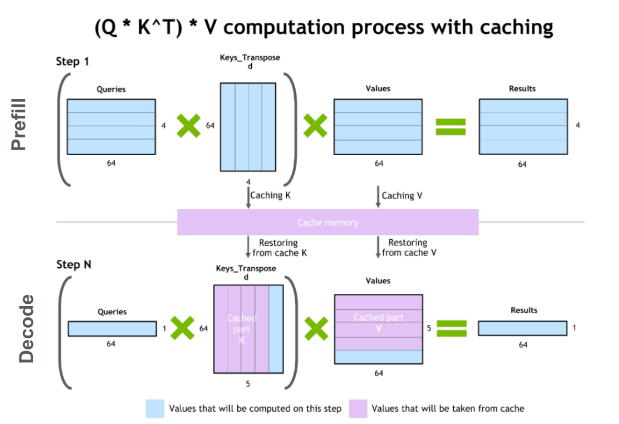
KV 캐시에 관한 것도 예시를 통해 설명하도록 하겠다.
우리는 다시 “hello how are you?” 뒤에 나오는 토큰을 예측하기로 한다. 다음에 나올 토큰은 “i”로 가정하겠다.
- 이전에 우리는 입력 프롬프트(”hello how are you”)가 처음 들어왔을 때 Query, Key, Value를 모두 계산했었다. 그리고 새로운 토큰 "?"를 추가하였다. (1. 입력 처리 단계)
- 이후 새로운 토큰(”i”)을 예측할 때, 이전의 과정처럼 다시 모든 토큰들("hello", "how", "are", "you", "?")에 대해 가중치 행렬을 곱하여 Query, Key, Value를 얻는 것은 비효율적이다. 따라서, Query는 새로 추가된 토큰("?")에 대해서만 생성되며 Key, Value는 캐싱해둔 기존 값에 새 값(K_5, V_5)를 추가하는 방식으로 업데이트된다. (2. 출력 생성 단계)
그러면 Q = [Q_5], K = [K_1, K_2, K_3, K_4, K_5], V = [V_1, V_2, V_3, V_4, V_5] 이렇게 Q, K, V가 구성된다. - 즉, 기존의 Query 행렬 (Q_1, Q_2, Q_3, Q_4) 은 새로운 토큰을 예측하는 데 필요하지 않으므로, 새로운 Query(Q_5)만을 사용하여 연산을 수행한다. 하지만 Key, Value는 계속 유지되어야 하므로 기존에 캐싱된 값에 추가되는 방식을 반복한다.
이렇게 하면 LLM이 이전 모든 토큰을 다시 계산하는 것이 아니라, 캐싱된 값을 재사용하면서 빠르게 다음 토큰을 예측할 수 있다.
이러한 KV 캐시를 통해서 연산 최적화 및 실시간 성능 개선을 이룰 수 있다.
- 연산 최적화 관점에서는 전체 연산량을 O(N^2)에서 O(N) 수준으로 최적화시킬 수 있다.
KV 캐시가 없다면 매번 이전 토큰들에 대해 Query, Key, Value를 새롭게 생성하기에 토큰 길이 N에 따라 Key-Query 내적 연산이 행렬-행렬 연산이기에 O(N^2)만큼 소요된다. 하지만 KV 캐시를 통해 이전 Key, Value를 캐싱하여 재사용하면 Key-Query 내적 연산에서 새 Query와 기존의 Key-Value만 연산하므로 행렬-벡터 연산이 되어 연산량이 O(N)으로 줄어든다. - 실시간 성능 개선 관점에서는 KV 캐시를 사용하여 매 스텝의 연산량이 일정하게 유지되기 때문에 실시간 응답 속도를 보장할 수 있게 된다. KV 캐시가 없으면 매번 처음부터 다시 계산해야 해서 응답 속도가 너무 느려지게 된다.
근데 아직까지도 KV 캐시를 완벽하게 이해하지 못하는 나 같은 사람은 또 의문이 들수도 있다.
아니 ‘hello how are you’ 뒤에 올 ‘?’를 예측하는 과정에서 ‘you’만을 쿼리라고 두면 ‘you’와 나머지 ‘hello’, ‘how’, ‘are’과의 관계는 고려할 수 있겠으나 그 이전 토큰들, 즉 ‘hello’와 ‘how’, ‘hello’와 ‘you’와의 관계는 고려하지 못한다는 것 아니야?
정답은 ‘아니다’이다!
Key뿐만 아니라 Value를 저장함에 주목해야 한다. Key-Query 간의 유사도를 모두 반영한 Value를!
이 Value가 KV 캐시에 저장되기 때문에 나중에 새로운 Query가 들어오더라도 ‘hello’와 ‘you’ 또는 ‘hello’와 ‘how’ 같은 모든 토큰간의 관계는 여전히 고려된다. ‘hello how are’를 기반으로 ‘you’를 생성할 때, 이미 ‘hello’와 ‘how’ 간의 관계는 이미 Value에 반영되었고, 그 정보가 KV 캐시에 저장되었다. 따라서 Query에 이전 것들이 추가되지 않는다고 해서 기존 토큰들 간의 관계가 사라지는 것은 아니다. ‘you’만을 쿼리로 둬도 ‘hello how are you’ 전체를 고려해서 ‘?’를 예측하게 되는 것이다.
이것으로 LLM의 추론에 대해서 전반적인 것은 한번에 정리를 하였다. 샘플링 단계를 하나하나 밟아가며 예시를 통해 이해하는 것이 머리 속에 확확 박히는 구나를 느낄 수 있었다. 무조건적으로 트렌드를 따라가는 게 장사가 아니라 기초를 확실히 밟아놔야 이것에서 심화된 정보들도 더 깊게 받아들일 수 있음을 실감하며 앞으로도 기초에 더 집중해야 겠다는 생각을 하였다.
Reference
https://developer.nvidia.com/ko-kr/blog/mastering-llm-techniques-inference-optimization/
LLM 기술 마스터하기: 인퍼런스 최적화
트랜스포머 레이어를 쌓아 대규모 모델을 만들면 다양한 언어 작업에서 정확도가 향상되고, 퓨샷 러닝이 가능하며, 심지어 인간에 가까운 능력을 발휘할 수 있습니다. 이러한 파운데이션 모델
developer.nvidia.com
https://dytis.tistory.com/54#KV%20Cache-1
LLM 인퍼런스 훑어보기 (2) - KV Cache
앞선 포스트에서는 Large Language Model (LLM) 인퍼런스의 중요성과 왜 우리는 LLM을 효율적으로 활용해야 하는지를 알아보았다. 더불어, LLM을 이용한 문장 생성은 autoregressive generation이며, 해당 생성
dytis.tistory.com
'LLM > Inference' 카테고리의 다른 글
| vLLM의 주요 기술 및 전체적인 구조: PagedAttention, Continuous Batching, Speculative Decoding, Chunked Prefill (1) | 2025.04.02 |
|---|