
vLLM은 LLM을 쉽고 빠르게 추론 및 서빙할 수 있는 라이브러리로 PagedAttention과 Continous batching이 주요 기술로 꼽힌다. 이번 게시글에서는 vLLM이 어떤 특징을 가지고 있는지와 그 주요 기술들이 어떻게 LLM 성능 최적화를 이뤄내는지에 대해 알아보도록 하겠다.
vLLM의 특징
vLLM은 LLM이 문장을 빠르게 생성하도록 하는 기법들을 활발하게 지원한다.
- 최첨단 서빙 처리량 제공
- PagedAttention으로 key, value 메모리를 효율적으로 관리
- 입력으로 들어오는 요청에 대해서 Continous batching 처리 가능
- CUDA/HIP 그래프를 통해 빠르게 모델 실행
- GPTQ, AWQ, FP8 KV Cache 등 다양한 양자화 기법 지원
- FlashAttention 및 FlashInfer와 통합된 최적화된 CUDA 커널
- 추측 디코딩 및 청크 단위 프리필 지원
vLLM은 여러 모델, 알고리즘에 대해 유연하고 사용 편의성을 고려하였다.
- hugging face 모델과의 원활한 통합
- 병렬 샘플링, 빔 서치 등 다양한 디코딩 알고리즘을 통한 고성능 서빙
- 분산 추론을 위한 텐서 병렬화 및 파이프라인 병렬화 지원
- 스트리밍 출력 지원
- OpenAI 호환 API 서버 제공
- NVIDIA GPU, AMD CPU/GPU 등 다양한 하드웨어 지원
- 프리픽스 캐싱 및 다중 LoRA 지원
공부 예정 키워드 : Flash Attention, 양자화, 추측 디코딩, 디코딩 알고리즘, 다중 LoRA
Paged Attention
배경
모델 추론을 위해 할당되는 GPU 메모리는 사진과 같은데,
- 모델 파라미터를 저장하는 공간,
- KV 캐시를 저장하는 공간,
- 여기서 KV 캐시는 새로운 토큰을 생성할 때마다 이전 모든 토큰들에 대한 Key, Value를 중복 연산하는 비효율적인 연산을 막고자 이전에 생성된 토큰들에 대한 키와 값 벡터 결과를 KV 캐시에 저장했다가 불러와서 재사용하는 기법을 말한다.
- 순전파 연산을 위한 메모리(기타) 등으로 구성된다.

LLM의 처리량을 크게 향상시켜 GPU를 효율적으로 활용하기 위해서는 배치 크기를 늘려야 한다. 배치의 크기가 클수록 많은 요청들을 병렬적으로 처리할 수 있기에 배치의 크기를 키우는 것이 효율적이기 때문이다. GPU 메모리에서 모델 파라미터가 차지하는 메모리 크기는 배치 크기와 상관없이 고정되어 있으며, KV 캐시 메모리 크기에 따라 최대 배치 크기가 결정된다.
KV 캐시 메모리 크기 = 2bytes(fp16 기준) * 2(키와 값) * (어텐션 레이어 수) * (토큰 임베딩 차원) * (최대 시퀀스 길이) * (배치 크기)
따라서 배치 처리의 병목은 KV 캐시가 차지하는 메모리 크기이며, 더 큰 배치를 처리하기 위해서는 KV 캐시가 저장되는 메모리를 효율적으로 관리할 수 있어야 한다.
기존 문제점
기존의 KV 캐시는 앞으로 사용할 수도 있는 메모리를 연속적으로, 요청의 최대 길이만큼 미리 잡아두면서 GPU 메모리를 많이 낭비한다는 문제점이 있다.
- 내부 단편화(internal fragmentation) : 기존 KV 캐시는 몇 개의 토큰을 생성할 지를 알 수 없기 때문에 최대 생성 토큰 수만큼 미리 메모리 예약해둬 일부 사용되지 않는 메모리 공간이 발생하기도 한다.
- 외부 단편화(external fragmentation) : 각 요청마다 사전에 할당된 메모리의 크기가 다르기 때문에 요청 할당 공간과 요청 할당 공간 사이 사용되지 않는 메모리 공간이 발생하기도 한다.
- 기존의 KV 캐시는 요청에 따라 물리적인 메모리를 할당하기 때문에 병렬 샘플링이나 빔 서치 등 병렬 디코딩 알고리즘을 사용 시 프롬프트나 일부 생성 토큰의 KV 캐시가 중복됨에도 공유가 불가능하다는 문제점이 있음
- 병렬 디코딩: 동일한 입력 프롬프트에서 여러 개의 출력을 생성하는 방법
- 빔 서치: 각 iteration마다 top k개의 후보군을 결정하는 방법
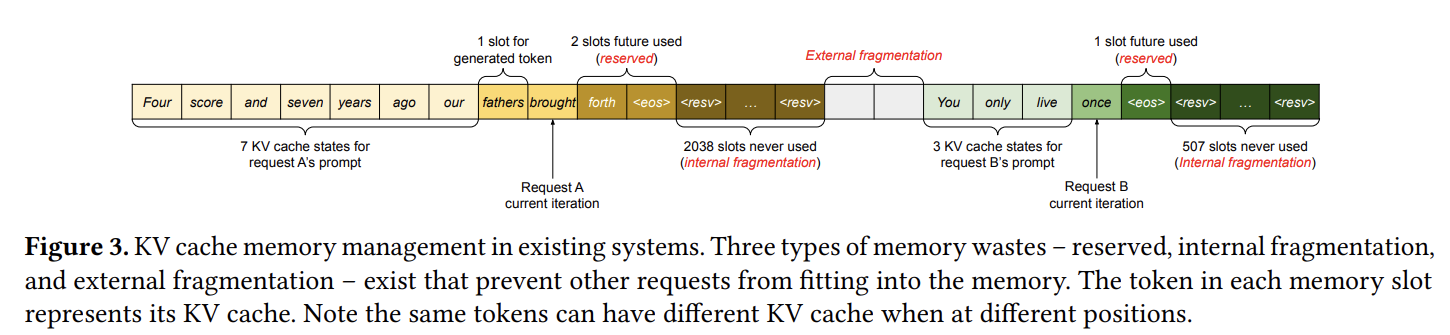
PagedAttention은 무엇일까?
PagedAttention은 운영체제의 페이징 시스템에서 영감을 받아, KV 캐시를 KV 블록으로 나누고 논리적 메모리와 물리적 메모리를 연결하는 블록 테이블을 관리, 실제로는 물리적으로 연속된 메모리를 사용하지 않으면서도 논리적 메모리에서는 연속적으로 보이도록 만든 KV 캐시 관리 기법을 말한다.
- 운영체제의 페이징 시스템 : 메모리를 고정 크기의 페이지로 분할한 후 가상 주소를 물리 주소로 변환하는 페이지 테이블을 사용, 미리 일정 크기의 메모리 예약할 필요없이 비연속적인 물리 메모리 페이지들에 저장하는 기법을 말한다.
- 블록 단위로 메모리를 예약하기 때문에 생성이 종료되어 배정되지 않은 메모리가 낭비되더라도 최대 (블록 크기-1) 메모리 크기만큼만 낭비하게 되어 낭비되는 메모리의 양을 크게 줄일 수 있다. (예를 들어 최대 토큰 크기가 2048이라고 하면, 이전에는 최대 2047만큼 낭비 가능)
- 논리적 메모리와 블록 테이블을 관리하여 다양한 디코딩 방식에서 물리적 KV 블록을 공유하며 메모리를 절약할 수 있다.
- 병렬 디코딩 : 두 개의 sequence에 대한 논리적 KV 블록은 동일한 입력 프롬프트의 KV 블록으로 매핑되어 있음, 생성하다가 두 sequence가 생성하는 sample이 달라진다면 copy-on-write 메커니즘을 사용하여 물리적 KV 블록 fork
- 빔 서치 : beam candidate 블록을 공유하며 기존의 KV 캐시 복사의 메모리 복사 오버헤드를 줄임
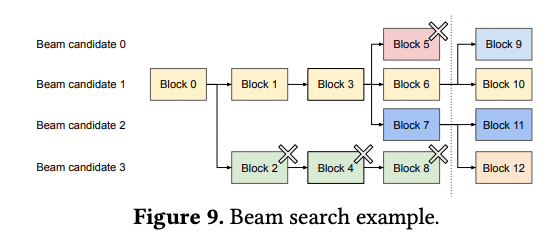


위의 그림 예시를 기반으로 Paged Attention의 동작을 설명할 수 있다.
- 처음 입력 프롬프트로 “Four score and seven years ago out”이 입력됨
- KV 캐시를 크기 4의 KV 블록으로 분할함
- 논리적 KV 블록에서는 Block 0, 1에 순차적으로 채워짐, 그 이후 생성되는 fathers, brought도 순차적으로 block 1, 2에 채워짐
- 하지만 물리적 KV 블록에서는 Block 7, 1, 3에 저장하고 논리적 블록과 물리적 블록이 어떻게 연결되는지는 블록 테이블에서 관리함
Continuous Batching
기존 문제점
기존의 정적 배치(static batching)의 경우, 한 번에 여러 개의 입력을 받아 모두 추론이 끝날 때까지 기다려야 한다.
배치 내 일부 입력들에 대해 생성이 종료된 이후에도 다른 입력 데이터의 추론을 기다리면서 대기 시간이 길어지고, 생성이 일찍 종료되는 문장이 있으면 해당 요청이 점유한 리소스를 배치의 모든 요청이 완료될 때까지 사용할 수 없다. 따라서, 처음에는 배치 크기만큼에 대해 추론을 수행했지만 이후에는 병목인 한 요청에 대해서만 추론하게 된다. 결과적으로 배치 크기가 작아져 GPU를 비효율적으로 사용하게 된다.
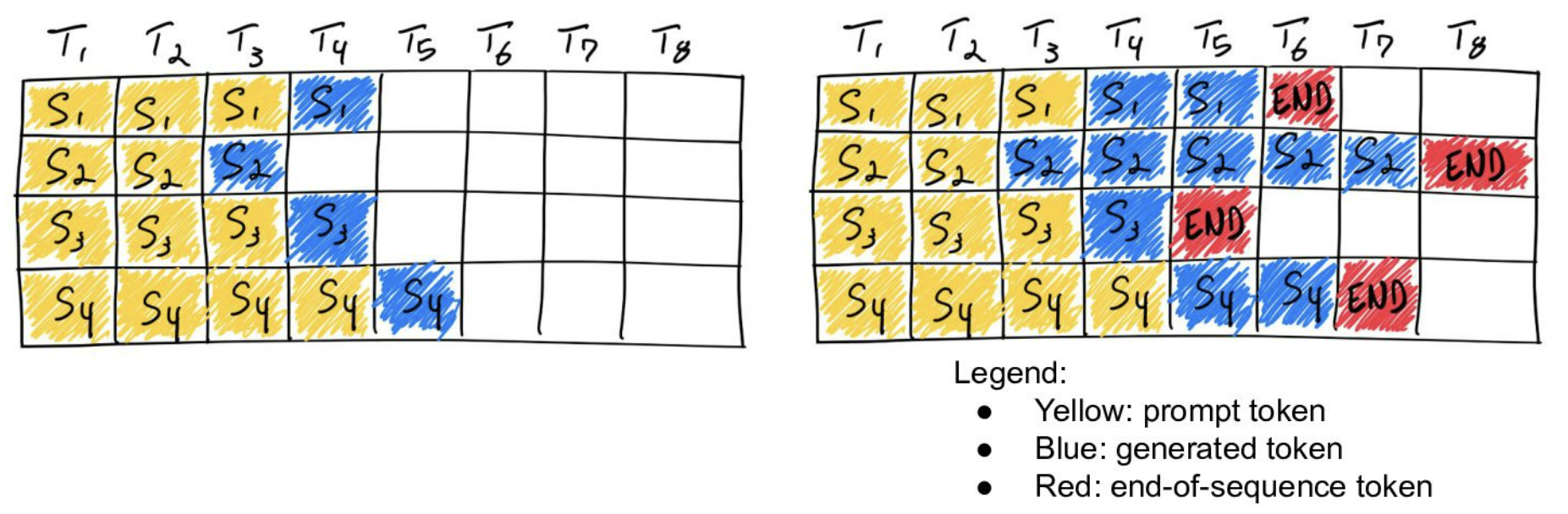
동적 배치(dynamic batching)의 경우, 비슷한 시간대에 들어오는 요청들을 하나의 배치로 묶어 배치 크기를 키우는 전략이다.
딥러닝 모델을 활용하여 서비스를 제공하는 경우, 언제 얼마만큼 사용자가 요청을 보낼지 예측할 수 없다. 예측 불가능성 때문에 사용자가 요청을 보낼 때마다 추론을 수행하게 되면 가장 먼저 요청을 보낸 사용자는 빠르게 결과를 받아볼 수 있으나, 다음에 요청을 보낸 사용자는 이전 요청이 추론되고 자신의 요청이 처리될 때까지 대기해야 한다.
이러한 문제를 해결하기 위해, 사용자가 요청을 보내더라도 바로 추론을 시작하지 않고 일정 시간동안 대기하면서 요청들을 수집한 후 한 번에 처리할 수 있도록 한다.

만약 첫 번째 요청(추론시간: 3ms)이 들어오고 1ms 뒤에 두 번째 요청(추론시간: 5ms)이 들어온 상황을 가정해보자.
| 첫번째 요청의 사용자의 대기시간(ms) | 두번째 요청의 사용자의 대기시간(ms) | |
| 정적 배치(static batching) | 3 | 8(= 3+5) |
| 동적 배치(dynamic batching) | 4 (= 1+3) | 5 |
하지만 이렇게 배치를 구성하여도 생성하는 토큰 길이의 차이로 인해 처리하는 배치의 크기가 점점 줄어 GPU를 비효율적으로 사용하게 되는 문제는 해결되지 않는다.
Continuous Batching
연속 배치(Continuous Batching) 전략은 배치의 모든 추론이 끝날 때까지 대기하지 않고 하나의 토큰 생성이 끝날 때마다 생성이 종료된 문장은 제거하고 새로운 문장 추가하는 배치 처리법을 말한다. 대기하지 않아도 되며 일찍 종료된 문장의 리소스의 경우 바로 다음 요청을 받을 수 있기에 GPU를 효율적으로 사용 가능하다.

그 외 LLM 성능 최적화 기법
CUDA/HIP 그래프
반복적인 연산을 미리 그래프로 저장하여 CPU 개입 없이 GPU에서 빠르게 실행하는 최적화 기법
- LLM의 디코딩 과정은 대부분 반복적인 연산 패턴을 가진다. 예를 들어, 토큰을 하나씩 생성하면서 입력은 길어지고, 이전 연산 패턴이 거의 동일하게 유지된다.
- 보통 PyTorch와 같은 프레임워크에서 LLM을 실행할 때는 동적 커널 호출 방식으로 실행된다. 이게 무슨 말이냐면 모델이 한 스텝을 수행할 때마다 개별적인 CUDA 커널이 실행되고, CPU가 이 커널 실행을 계속해서 관리해야 한다는 뜻이다.
- 근데 CUDA/HIP 그래프를 사용하면 모델 실행 과정에서 반복적으로 수행되는 연산을 그래프 형태로 미리 기록(캡쳐)하고, 이후에 이 그래프를 재사용하여 실행 속도를 높일 수 있다.
예를 들어, LLM의 디코딩 가정에서 수행되던 행렬 연산, 어텐션 연산, 활성화 함수 등의 연산을 그래프로 만든다. 이후, 같은 연산이 필요할 때 개별 커널을 하나씩 실행하는 것이 아니라 미리 저장된 실행 그래프를 GPU에서 바로 실행하므로써 CPU 개입을 줄이고 커널 실행 간 오버헤드를 줄인다. - 하지만 그래프를 생성하는 과정에서 초기 실행 시간이 필요하며, 다이나믹한 연산(e.g. 입력 크기가 계속 변하는 경우)에 대해서는 그래프 재사용이 어려울 수 있다.
추측 디코딩 (Speculative Decoding)
보조 모델이 여러 개의 토큰을 미리 예측하고, 주 모델이 이를 검증하는 방식으로 디코딩 속도를 높이는 기법
- 일반적인 LLM의 디코딩 방식에서는 한 번에 하나의 토큰만 생성한다.
- 추측 디코딩을 통해 보조 모델(작은 모델)이 미리 여러 개의 토큰을 어림짐작하고, 주 모델(LLM)이 이를 검증하는 방식을 사용하여 디코딩 속도를 높일 수 있다. 특히 보조 모델의 성능이 좋은 경우에는 여러 개의 토큰을 한 번에 확정할 수 있어 속도가 빨라진다. 일부 토큰이 틀렸다면 틀린 시점부터 다시 주 모델이 일반적인 방식으로 디코딩한다.
- 보조 모델이 입력 프롬프트에 대해 2개의 토큰을 먼저 생성한다.
- 주 모델은 입력 프롬프트와 보조 모델이 생성한 2개의 토큰을 입력으로 받고 다음에 올 1개의 토큰을 생성한다.
- 주 모델은 새로운 토큰을 생성하는 과정에서 보조 모델이 생성한 2개의 토큰을 주 모델이 동일하게 생성했었을지를 판단한다. 주 모델이 동일하게 생성했었을 것으로 판단되면 2개의 토큰을 승인하여 총 3개의 토큰을 생성하게 된다.
이 과정에서 보조 모델은 추론에 5ms이, 주 모델은 추론에 50ms이 걸린다고 가정하자.
일반적으로는 3개의 토큰을 생성하는 데에 50ms * 3 = 150ms이 걸리겠지만, 보조 모델의 결과를 검증하는 방식을 통해 5ms * 2 + 50ms = 60ms으로 디코딩 시간을 단축시킬 수 있다.
청크 단위 프리필(Chunked Prefill)
긴 입력 프롬프트를 작은 청크로 나누어 병렬로 처리하여 프리필 속도를 최적화하고 메모리 사용을 줄이는 기법
- 프리필(Prefill)은 입력 프롬프트에 대한 토큰들을 처리하여, key, value를 생성하는 단계, 즉 입력 프롬프트가 주어졌을 때 인코딩하는 단계를 말한다.
- 기존에는 프롬프트 전체를 한 번에 처리했기에, 입력의 길이가 길면 속도가 느려지는 문제가 있었다.
- 청크 단위로 나누어 인코딩을 진행하므로써, 입력의 길이가 길어도 효율적으로 인코딩할 수 있다.
vLLM의 전체적인 구조 및 동작 원리

- LLMEngine : 실제 문장 생성을 담당하는 엔진으로, 생성에 필요한 컴포넌트들(워커, 스케줄러, 토크나이저 등)을 모두 생성하고 초기화함
- 중앙 집중식 스케줄러 : 요청들의 우선순위를 결정하고 GPU 워커에 할당함
- GPU 워커 : 실제 모델 추론을 수행함, 여러 GPU 워커가 동시에 작업을 처리함
- KV 캐시 매니저 : KV 캐시의 할당 및 해제를 관리함
- 최대 24배 빠른 vLLM의 비밀 파헤치기 > 동작 원리 자세히 설명해놓은 블로그
- 스케줄러가 요청을 받음, 요청의 우선순위를 결정하고 적절한 GPU 워커에 할당함
- KV 캐시 매니저가 KV 캐시를 고정 크기의 블록으로 나눈 후 필요한 만큼의 KV 블록을 동적으로 할당함 (Paged Attention)
- 입력된 프롬프트의 토큰을 처리하고 초기 KV 캐시를 계산하여 물리적 KV 블록에 저장 (Paged Attention)
- 모델은 새로운 토큰을 생성, 새로운 토큰이 생성될 때마다 KV 캐시를 계산하여 물리적 KV 블록에 저장
- 텐서 병렬화나 파이프라인 병렬화를 통해 여러 GPU 워커가 동시에 다른 요청을 처리함
- 스케줄러는 지속적으로 새로운 요청을 받아 처리중인 배치에 추가 (Continuous Batching)
- 생성된 토큰들은 클라이언트에 반환됨
'LLM > Inference' 카테고리의 다른 글
| LLM은 어떻게 추론하는가? Transformer부터 GPT, KV 캐시까지 (0) | 2025.03.31 |
|---|