저번에 Knowledge distillation에 대해서 공부했었는데 LLM이라는 거대 모델에서는 어떻게 활용할 수 있는지 알아보았다.
참고로 이 논문 리뷰를 읽기 전 아래의 Knowledge distillation 정리글을 읽으면 더 잘 이해가 될 것이다.
https://soyoonblog.tistory.com/entry/Knowledge-Distillation-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
Knowledge Distillation, 무엇인가?
최근 큰 LLM들을 돌리며 모델 메모리, 연산 시간 등의 자원들을 신경쓰게 되었고, 큰 모델의 성능을 최대한 지키면서 모델 크기는 크게 축소시킬 수 있는 Knowledge Distillation에 대해 관심이 생겨서
soyoonblog.tistory.com
What did authors try to accomplish?
문제점 1: LLM은 메모리 비효율적이며 계산 집약적이어서 실용 애플리케이션에 배포하기 어렵다.
문제점 2: 따라서 연구자들은 더 작은 모델을 학습시키기 위한 방법을 모색하였으나 해당 방법들로 LLM만큼의 성능에 도달하려면 많은 학습 예제를 필요로 한다.
- 모델 크기를 줄이기 위해 사람이 직접 주석을 단 데이터로 fine-tuning
- LLM이 생성한 레이블로 knowledge distillation(black box kd)
해결방법: Distilling step-by-step
- 일반적인 fine-tuning, knowledge distillation보다 더 적은 학습 예제로 더 작은 모델을 학습시킬 수 있는 방법 제시
- 주요 아이디어: LLM의 ‘합리적 설명’ (rationales)를 추가적인 감독 자료로 활용하여 학습시킴
- 기존의 knowledge distillation에서의 LLM: label 뽑아내는 소스
→ knowledge distillation step-by-step에서의 LLM: 사고 과정을 가지는 에이전트 - 예를 들어, “제시의 방은 길이가 11피트이고 너비가 15피트입니다. 그녀는 이미 16제곱피트의 카펫을 가지고 있습니다. 전체 바닥을 덮기 위해서 얼마나 더 많은 카펫이 필요합니까?”라는 질문이 LLM에 입력되게 된다면,
- LLM이 CoT(Chain-of-Thought) 기술을 사용하여 “면적=길이x너비. 제시의 방은 11x15제곱피트입니다.”라는 합리적 설명을 제공하여 입력과 최종 답변인 “11x15-16”을 연결할 수 있게 된다.
- 이 때 LLM에서 추출된 합리적 설명을 다중 작업 훈련을 통해 더 작은 모델을 학습시키는 데에 사용하게 되는데, label 예측과 합리적 설명(이유) 예측을 같이 진행하기에 다중 작업 훈련이라고 한다.
- 기존의 knowledge distillation에서의 LLM: label 뽑아내는 소스
What were the key elements of the approach?
Distilling step-by-step은 다음과 같은 2 step으로 진행된다. (그래서 step-by-step인가..?)
- Extracting rationales from LLMs
LLM에게 라벨링이 되어 있지 않은 데이터, 즉 비라벨 데이터를 입력하여 label과 이에 대한 합리적 이유(rationales)를 생성하도록 한다. - Training smaller models with rationales
각각 생성된 label과 합리적 이유로 더 작은 모델을 학습한다.
이 때 모델은 label 예측과 합리적 이유 예측, 두 가지 작업을 동시에 수행한다.
1. Extracting rationales from LLMs
few-shot CoT(Chain of Thoughts) 프롬프트를 통해 LLM으로부터 예측한 답에 대한 이유를 추출한다.

참고로 나는 CoT에 대해 모르기 때문에 ChatGPT에게 질문했다!
Chain of Thought, 즉 CoT 프롬프트는 모델이 단계적으로 논리를 전개하며 문제를 해결하도록 유도하는 프롬프트 기법을 말한다. 단순하게 정답을 출력하는 것이 아니라 단계적으로 설명하도록 유도하여 더 정확하고 논리적인 답변을 얻을 수 있다.
예시를 들자면,
- 일반적인 프롬프트: “사과 3개와 오렌지 2개를 합하면 몇 개입니까?” ⇒ 모델 응답: 5
- CoT 적용 프롬프트: “사과 3개와 오렌지 2개가 있습니다. 총 과일 개수를 구하는 방법을 단계적으로 설명하시오.” ⇒ 모델 응답: 1. 사과는 3개입니다.
- 오렌지는 2개입니다.
- 총 개수를 구하려면 3+2를 계산합니다.
- 3+2=5이므로, 총 과일 개수는 5개입니다.
위의 예시와 같이 “단계적으로 설명하시오”를 추가하였더니 답을 구하는 과정을 논리적으로 출력한다.
더 놀라운 점은 이렇게 단계적 사고를 유도하면 더 정확한 답을 도출하게 된다는 것이다.
따라서 수학, 논리 문제에서 CoT 프롬프트를 사용하면 더 강력한 성능을 발휘한다고 한다.
CoT 프롬프트는 few-shot, zero-shot으로 나눌 수 있다.
- few-shot CoT: 본 논문에서 사용한 프롬프트 기법으로, 답과 함께 답을 구하는 과정이 포함된 몇 개의 예시를 제공하여 패턴 학습을 유도한다.
- zero-shot CoT: 위의 예시에서 사용된 프롬프트 기법으로, “단계적으로 생각해보자” 라는 유도 문구를 프롬프트에 추가하여 논리적 사고를 유도한다.
2. Training smaller models with rationales
기존의 fine-tuning, knowledge distillation은 사람이 주석을 작성한(→fine-tuning) 또는 LLM이 예측한(→knowledge distillation) 토큰과 모델이 예측한 토큰 사이의 cross-entropy loss를 최소화하며 학습한다.

식은 위와 같은데 여기서 ℓ 은 cross-entropy loss이고 f(x_i)은 모델이 예측한 토큰, y_i는 타겟 토큰을 말한다.
본 논문에서의 distilling step-by-step의 loss는 LLM이 생성한 “합리적 이유”를 보조 감독으로 사용하는 아이디어에서 도출할 수 있다.
먼저 LLM이 생성한 “합리적 이유”를 어떻게 활용할 것인지에 대한 선행 연구에 대해 알아보자
문제점: 다른 연구에서 이미 LLM이 생성한 “합리적 이유”를 추가적인 모델의 입력으로 사용하였었다.
아래의 식은 선행 연구의 loss인데, r_hat_i (합리적 이유)가 x_i(입력)과 함께 f(모델)에 같이 입력된 것을 볼 수 있다.
이러한 방식이 받아들여 지지 않은 이유는 모델의 배포 때문이다. LLM이 이유를 생성하는 과정에서 학습하는 모델이 LLM에 의존하게 되므로, 최종 모델이 배포될 때도 LLM에 의존하게 된다.

해결방법: 따라서 본 논문에서는 LLM이 생성한 “합리적 이유”를 입력이 아닌 모델의 합리적 이유 생성의 보조 감독으로 사용하였다. 따라서 모델은 기존의 방법과 같은 레이블 예측뿐만 아니라 이유 생성까지, 두 가지 작업을 동시에 학습하게 된다.

그리고 이러한 다중 작업 학습은 loss가 두 개의 term으로 구성되었다는 것에서 확인할 수 있다.

- 레이블 예측 손실: 위에서 설명한 타겟 토큰과 예측 토큰의 cross-entropy loss이다.

- 이유 생성 손실: LLM이 생성한 이유와 모델이 생성한 이유간의 cross-entropy loss이다. 두 텍스트 간의 cross-entropy loss는 모델이 이유를 생성할 때 예측한 확률 분포와 정답 텍스트의 원핫 벡터를 사용하여 cross-entropy loss를 계산한다.
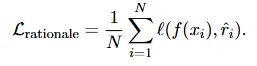
갑자기 cross entropy loss에 대한 개념이 모호해져서 전에 공부했던 내용을 참고하고 chatgpt에게 질문했다.
cross entropy loss는 두 확률 분포 상의 유사성을 측정하는데 사용되며, LLM에서의 cross entropy loss는 모델이 예측한 다음 토큰의 확률 분포와 실제 정답의 원핫 벡터의 확률 분포 사이의 차이를 측정한다!
experiments는 생략하도록 하겠다… 후에 필요하다면 추가하여 리뷰하는 것으로~
What i can do or think
knowledge distillation에 대해 알아봤고 LLM에서 어떻게 특수하게 합리적 이유를 잘 distilling할 수 있는지도 알 수 있었다. 아마 knowledge distillation에 대한 공부는 당분간은 더 이어지지 않을 것 같으나, 후에 더 다양한 distillation 방법에 대해 알아볼 수 있는 기회가 주어졌으면 좋겠다.