반응형
What did authors try to accomplish?
문제점과 해결방법을 기반으로 해당 논문에서 기여한 바
문제점 : 커뮤니티에서 다양한 효율적인 미세 조정 방법이 기여되고 있지만, 서로 다른 LLM에 대해 이러한 방법을 조정하고 통합할 수 있는 체계적인 프레임워크가 부족하다.
해결점 : LLM의 효율적인 파인튜닝을 위한 통합 프레임워크, LLAMA-FACTORY 개발
- Data Worker, Model Loader, Trainer 모듈간의 종속성을 최소화하여 다양한 모델, 데이터셋, 훈련 방법에 대해 통합적으로 사용할 수 있는 프레임워크 제공
- 커맨드 라인이나 웹 인터페이스를 통해 코드 작업 없이 LLM을 커스터마이즈하고 파인튜닝 가능하도록 함
What were the key elements of the approach?
Method 기반 해당 논문 주요 아이디어
Llama-Factory의 주요 모듈 : Model Loader, Data Worker, Trainer
LLAMA-FACTORY는 Model Loader, Data Worker, Trainer 세 모듈로 구성되어 있다.
LLM 평가에 집중하여 논문을 읽고 있는 나는 Model Loader와 Data Worker에 집중하여 읽었다.
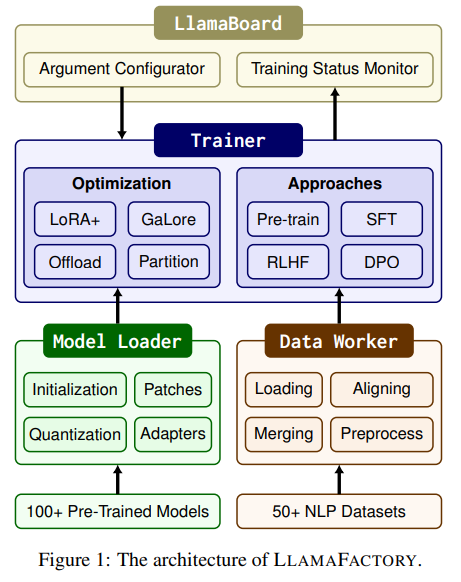
Model Loader
- Model Initialization : Transformers 라이브러리에서 제공하는 자동화된 클래스들로 모델과 토크나이저 로드함
- Model Patching : S2 Attention 활성화, Flash Attention 사용, 동적 레이어의 과도한 분할 방지, Deep Speed ZeRO와 같이 기존 코드에 동적으로 변경 추가함
- Model Quantization : LLM.int8, QLoRA, GPTQ, AWQ, AQLM과 같은 양자화 방법 사용하여 모델의 가중치를 낮은 정밀도(8비트 또는 4비트)로 변환함
- Adapter Attaching : 모델의 일부 파라미터를 동결하고 새로운 학습 가능한 파라미터(어댑터)를 추가하여 특정 작업에 맞춰 조정함
- Precision Adaptation : 사전 학습된 모델의 부동 소수점 정밀도를 컴퓨팅 장치의 성능에 맞게 조절함
Data Worker
- Dataset Loading : Datasets 라이브러리를 사용하여 Hugging Face Hub의 원격 데이터셋 또는 로컬 데이터셋을 로드함, 기본적으로 데이터셋을 다운로드하여 사용하나 데이터셋이 너무 커서 저장할 수 없는 경우 데이터셋 스트리밍 기능을 통해 데이터를 다운로드하지 않고 순회할 수 있는 방법 제공함
- Dataset Aligning : 각 데이터셋의 구조를 정의하여 다양한 작업에 적합한 표준 구조로 변환함

- Dataset Merging : 비스트리밍 모드에서는 데이터셋들을 연결한 후 shuffle, 스트리밍 모드에서는 서로 다른 데이터셋에서 교대로 데이터를 읽는 방식으로 데이터셋 병합
- Dataset Pre-processing : 모델 유형에 따라 자동으로 선택할 수 있는 수십 개의 chat template 제공함
Trainer
- 효율적인 파인튜닝 방법들을 적용하는 방법으로 plug-and-play 구현
- 효율적인 학습, 모델 공유 RLHF, 분산 학습에 대한 내용이지만 후에 필요 시 작성 ..
LLaMA-Factory의 모델 추론 및 평가 방법
모델 추론
- Data Worker로부터 받은 Chat Template를 사용하여 모델 입력을 구성
- Transformer와 vLLM 두 가지 라이브러리를 활용하여 모델 출력 샘플링 지원
- OpenAI 스타일의 API 구현하여 비동기 LLM 엔진과 vLLM의 Paged Attention 기법을 활용함, 높은 처리량을 제공하는 동시 추론 서비스를 가능하게 함
모델 평가
- Multiple Choice Dataset (MMLU, CMMLU, C-Eval)을 사용
- BLUE-4, ROUGE와 같은 텍스트 유사성 점수 계산
LLaMA-Factory에 적용된 효율적인 파인튜닝 방법들
Efficient Optimization
- 목적 : LLM의 파라미터를 조정하면서 비용을 최소화
- Freeze-tuning : 대부분의 파라미터를 freeze하고 일부 디코더 레이어의 파라미터만 조정하여 학습하는 방식
- Gradient low-rank projection(GaLore) : gradient를 저차원 공간으로 투영하여 아키텍처의 모든 파라미터를 메모리 효율적으로 학습하는 방식
- BAdam : 블록 좌표 하강법(BCD)를 이용하여 많은 파라미터를 효율적으로 최적화하는 방식
- 블록 좌표 하강법 : 일반적인 좌표 하강법은 여러 변수로 이루어진 함수에서 하나의 변수만 고정한 뒤 그 변수를 기준으로 최적화를 반복하는 반면, 블록 좌표 하강법은 여러 변수를 하나의 블록으로 묶어서 각 블록 단위로 최적화를 수행함
- Badam : 기존의 Adam을 변형한 최적화 알고리즘으로, 모든 매개변수에 대해 개별적으로 동작하는 것이 아닌 매개변수 블록 단위로 최적화를 수행함. 각 블록의 구조적 특성을 더 잘 반영한 업데이트 수행됨 (대규모 모델에 적합함)
- low-rank adaptation(LoRA) : 모든 사전 학습된 가중치를 freeze하고, 특정 레이어에 한 쌍의 학습 가능한 저차원 행렬을 도입하는 학습 방식
- 모델의 모든 파라미터를 학습시키는 대신 기존의 가중치 행렬을 고정한 상태로 그 행렬을 한 쌍의 작은 저차원 행렬로 분해하여 학습시킴, 학습에 필요한 파라미터 수 줄일 수 있음
- QLoRA : LoRA에 양자화를 도입하여 추가적으로 메모리 사용을 줄이는 학습 방식
- DoRA : 사전 학습된 가중치를 크기와 방향으로 나누고 성능 개선을 위해 방향 성분을 갱신하며 학습하는 방식
- LoRA+ : LoRA의 최적성을 극복하기 위해 제안된 접근법
- LoRA는 모델 훈련 중 성능이 최적화되지 않는 상황에서 하락세를 보일 수 있음
- 최적성 극복 방법 : 가중치 초기화 방식 개선, 학습률 조정 방식 최적화, 파라미터 조정의 유연성 증가, 더 많은 최적화 기법 통
- PiSSA : 초기화 시 사전 학습된 가중치의 주성분을 사용하여 수렴 속도를 높이는 학습 방식
Efficient Computation
- 목적 : LLM에서 필요한 연산 시간 및 공간 최소화
- Mixed Precision Training : 메모리 사용량을 줄이고 계산 성능을 향상시키기 위해 훈련 중에 다양한 정밀도를 사용하는 방법
- Activation Checkpointing : 메모리 사용량을 줄이기 위해 일부 활성화를 저장하지 않고 중간 결과를 재계산하는 방법, 메모리 사용량은 줄일 수 있지만 계산 비용 증가
- Flash Attention : 기존 attention 계산 개선하여 입력 및 출력의 메모리 지출을 줄이는 방법
- S2 Attention : shifted sparse attention을 사용하여 긴 컨텍스트의 메모리 사용량을 줄이는 방법
- 다양한 양자화 전략 : 낮은 정밀도의 표현을 사용하여 LLM의 메모리 요구량을 줄이는 방법
- LoRA : 양자화된 모델의 튜닝을 위해 사용되는 Adapter-based 기법
- Unsloth : triton을 사용하여 LoRA의 역전파를 구현하는 방법, 그래디언트 하강 중 부동 소수점 연산을 줄이고 LoRA 학습 시간을 단축함
What i can do or think
이 논문 기반으로 내가 무엇을 할 수 있고 어떤 것을 생각했는가
개발 중인 LLM 자동 평가 시스템의 시스템 아키텍처 개선
- Model Server 모듈 재구성
- Model Server의 기존 모듈 : 초기화(모델 및 데이터셋 초기화), 데이터 처리, 추론 및 평가, 결과 저장
- Model Server의 모듈 v2 : API Interface, Model Loader, Data Worker, Inference Engine, Evaluator, DB Connector , Monitoring
- API Interface : 다른 서버와의 API 제공
- Model Loader : 모델 및 생성 옵션, 양자화 기법 등 초기화
- Data Worker : Hugging face hub의 원격 데이터셋 또는 로컬 데이터셋 로드
데이터셋을 표준 데이터셋 구조에 맞게 변환, 여러 데이터셋을 사용할 경우 지정된 종류 및 비율에 따라 데이터셋 병합, Chat template을 사용하여 모델 입력 구성 - Inference Engine : vLLM으로 비동기 LLM 추론 실행, 배치 처리, 결과 생성
- Evaluator : 다양한 평가 메트릭 계산, 결과 분석
- DB Connector : 평가 결과 저장
- Monitoring : 성능 및 GPU 모니터링
- API Server 모듈 재구성
- API Server의 기존 모듈 : API, 로깅, QUEUE 관리
- API Server의 모듈 v2 : API Interface, Logging , Task Scheduler, DB Connector (용어 변경)
- API Interface : 다른 서버와의 API 제공
- Logging : 시스템 로그 관리, 에러 추적
- Task Scheduler : 모델 평가 request를 담는 내부 QUEUE 관리
- DB Connector : 평가 결과 조회 및 관리
더 알아볼 점
- 저번에 평가 데이터셋 조사하면서 생각했던 것인데 데이터셋이 평가하는 llm의 능력마다 데이터셋 형식이며 평가지표며 너무 다양하다.
=> Chat Template이나 데이터셋 변환 같은 통합된 데이터셋 처리에 대해 알아봐야겠다. - 시스템에 적용할 수 있는 효율적인 추론 방식에 대해 더 알아봐야겠다.
- Llama-Factory가 효율적인 파인튜닝을 위한 통합 프레임워크인 만큼, 해당 논문은 효율적인 학습을 위한 trend의 집합체였다.
LoRA, QLoRA, 양자화 기법 등 생소한 개념들이 많이 나왔고 Survey 논문 읽듯이 아주 얕고 넓게 효율적인 학습 기법에 대한 베이스를 쌓을 수 있었다.
일상 속에서도 효율을 추구하는 나는 효율적인 학습 및 추론에 매우 관심이 많다.
해당 논문을 시작으로 논문에 reference된 다른 논문들도 읽어나갈 수 있기를..
반응형